|
網站(zhàn)布局之TF-IDF算(suàn)法,說白了在我理(lǐ)解來(lái),這個(gè)算(suàn)法就是通(tōng)過一個(gè)的數(shù)學計(jì)算(suàn),來(lái)确定每個(gè)詞在文章中的權重,從而得(de)到一篇文章的關于詞的帶權重的向量,知道(dào)了這個(gè)以後就好辦了,之後什麽文章關鍵字提取、概述、不同的文章之前的相似性比較都引刃而解了。
求一個(gè)詞的權重就用到TF-IDF算(suàn)法,其實TF-IDF算(suàn)法是分為(wèi)TF(Term Frequency,縮寫為(wèi)TF)與IDF(Inverse Document Frequency,縮寫為(wèi)IDF)的計(jì)算(suàn)。
說起來(lái)也簡單,TF就是這個(gè)詞在文章中的詞頻,出現的次數(shù)比上(shàng)文章的總次數(shù)或者出現次數(shù)最高(gāo)的詞的個(gè)數(shù)。而IDF則是表示TF-IDF算(suàn)法分母上(shàng)加一是為(wèi)了防止分母為(wèi)零。
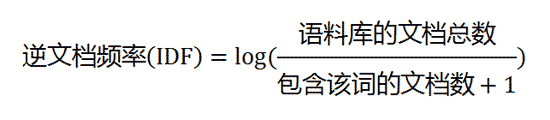
TF-IDF
這個(gè)數(shù)學的表達式也符合情理(lǐ),如果關鍵字(除去“的”、“為(wèi)了”之類的去除字)在越多(duō)的文檔中出現,它在本篇文章中的權重自然就低(dī)了,舉個(gè)簡單的例子:給你(nǐ)一個(gè)關鍵字計(jì)算(suàn)機,你(nǐ)一點也不知道(dào)這貨表達的意思,因為(wèi)(從這個(gè)算(suàn)法角度講)它在太多(duō)的文章中出現,但(dàn)是如果你(nǐ)的關鍵字為(wèi)0day就不一樣了,包含它的文檔數(shù)遠遠小(xiǎo)于包含關鍵字“計(jì)算(suàn)機”的文檔數(shù)。由此,如果在同一篇文章裏,如果“0day”與“計(jì)算(suàn)機”的TF(詞頻)相同,IDF就可(kě)以保證“0day”的權重較高(gāo)了。
基本的算(suàn)法就是這樣了,其實很(hěn)簡單,但(dàn)是這個(gè)算(suàn)法是基于這樣一個(gè)前提,關鍵詞越重要,出現的頻率越高(gāo)。同時(shí)忽略了詞出現位置的影(yǐng)響,所以這個(gè)算(suàn)法存在漏洞。
|




 2020端午節放假通(tōng)知
2020端午節放假通(tōng)知
